A Complete Solution to Extract Metadata From PDF Files


In this digital era, we all need to take backups in PDF File format from our documents. I noticed that many users on the Internet looking to extract metadata from PDF files. So, after a lot of searches, I am here with complete information and to provide you with an entire solution.
Here you will know how to export metadata from PDF files using the Manual method and a professional solution. So, let’s start the topic without further ado.
Manual Method to Extract Metadata from PDF
These are the two Manual Methods as per your demand. 1st Using Python 2nd Using Online Free Tools. 3rd Using Offline Software.
Method 1: Using Python Modules
- Download the pyPdf Tar.gz file from the internet.
- Now, extract the tar.gz using the following Modules: tar –xvzf ‘filename’
- Then, change your directory from the extracted folder.
- After that install by running python setup.py install modules.
- Below is the program code to extract the metadata from PDF files.
import pyPdf
def main():
# Enter the location of ‘ANONOPS_The_Press_Release.pdf’
# Download the PDF if you haven’t already
filename = <LOCATION_OF_THE_PDF>
pdfFile = pyPdf.PdfFileReader(file(filename,’rb’))
data = pdfFile.getDocumentInfo()
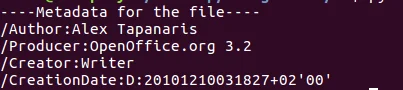
print “—-Metadata of the file—-”
for metadata in data:
print metadata+ “:” +data[metadata]
if __name__ == ‘__main__’:
main()
Then, you will get the Export metadata from the PDF file.
The Drawback of Using The Python Method
This Python Method is not for a non-technical person, if you don’t know about Python and don’t want to get hassle then skip this method.
Method 2: Using an Online Tool to Get Metadata From PDF
- Search on the internet Online for PDF Metadata extractor software.
- Open the website and then upload your PDF file to the online tool.
- Now, the user will get your metadata from the PDF.
The Disadvantage of Using an Online Tool
- Users can’t trust Online tools due to data security.
- Online Software can contain inappropriate materials.
- They don’t know whether their data online tool is stored on a server or not.
Professional Solution to Extract Metadata from PDF Files
To overcome this problem users can continue with this problem you can go with the PDF file Extractor Software. This tool was designed with the beginner for non-technical and technical users in mind. This Software can extract Bookmarks, hyperlinks, and metadata, images, Rich Media from PDF files. Also, it can extract text from PDF files. This Extractor Tool for PDF file format provided support for creating a folder for each pdf file attachment and exporting attachments into respective folders.
It ensures that there will be no data loss throughout the whole extractor process and maintains folder hierarchy in extracting metadata from PDF. Moreover, this software also works on Windows and Mac systems and it can extract protected PDF file in batch. Even, we have highlighted the most important features it has to offer in the following area. But firstly, we have to solve our problem and look at the software steps.
Benefits of Our Software
- Provide the option to extract Meta from multiple PDF files at once.
- The software can extract Hyperlinks, bookmarks, text, attachments, Inline Images, rich media, comments, and metadata from PDF files.
- The tool has special Apply Metadata Settings Options to save metadata into PDF, DOC, and DOCX.
- Create a new folder according to the PDF attachments file type and export it into new folders.
- The Software can maintain folder hierarchy and extract files from PDFs.
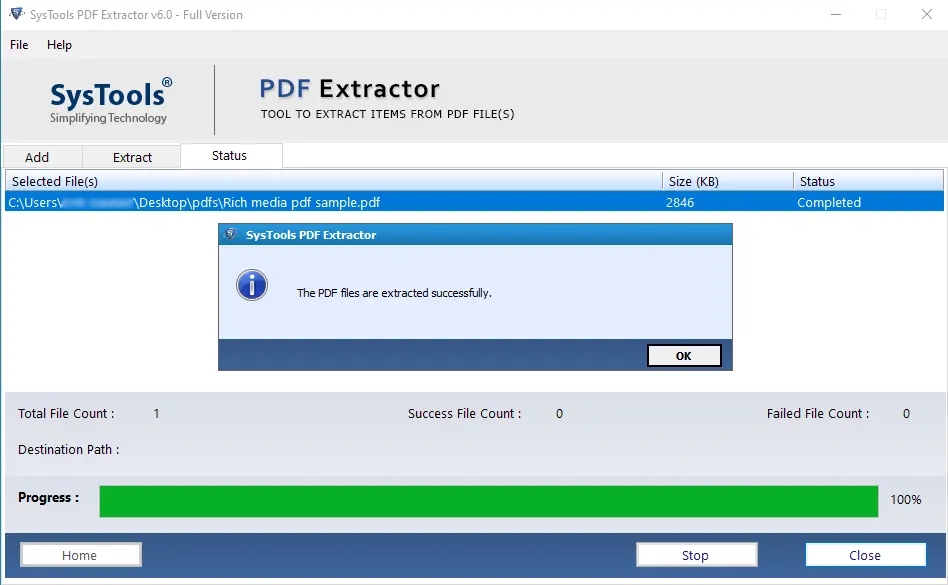
Step-by-Step to Export Metadata From PDF Documents
- Download and Run the Utility in your Operating (Windows & Mac) System to extract metadata from PDF files.
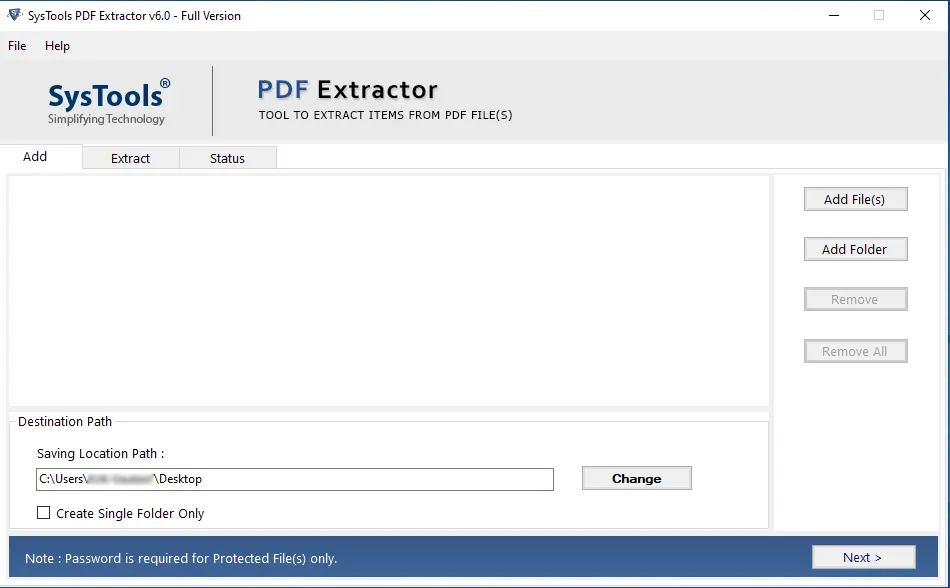
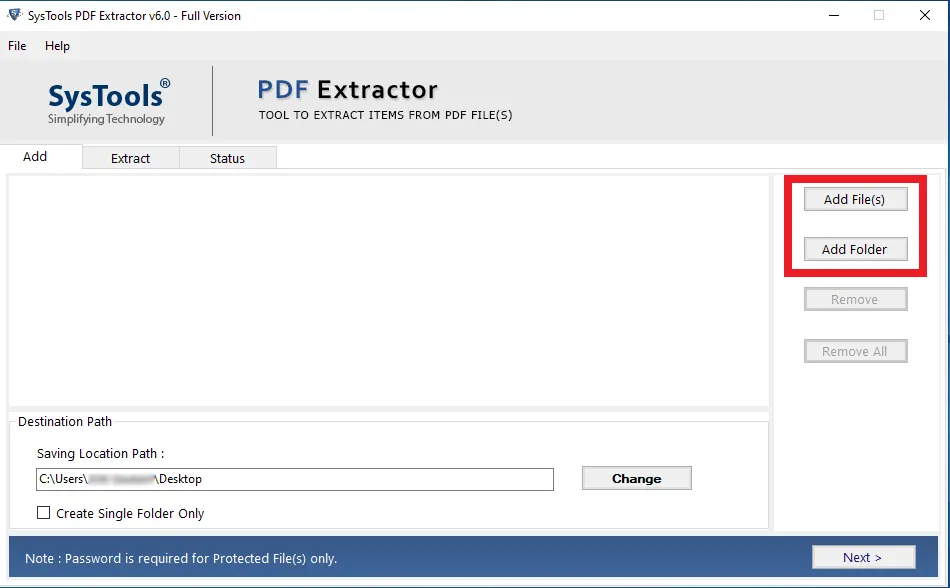
- Now, Click on Add file/Add folder option and add your PDF file to the software.
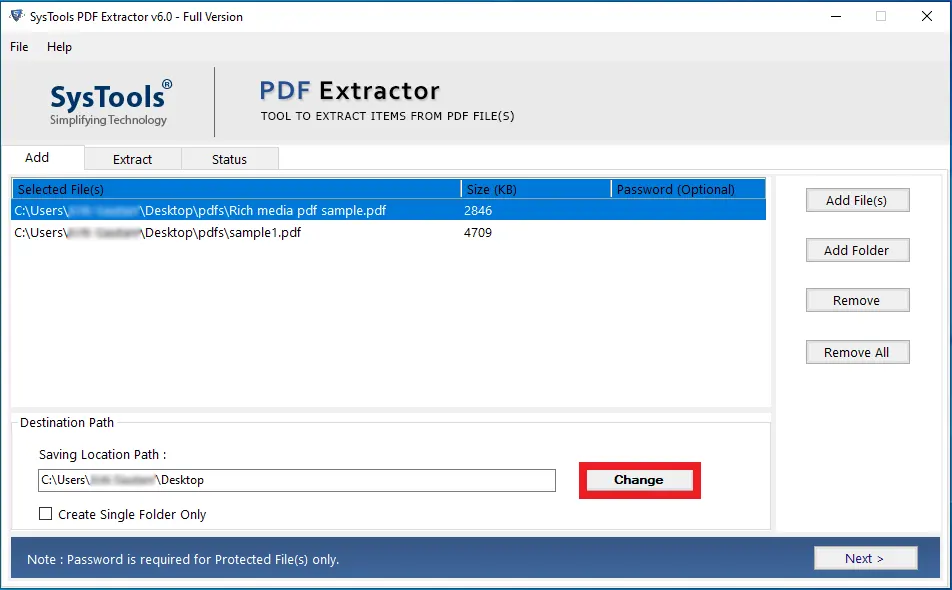
- Then, click on the Change button and choose your destination location.
- After that, click on the Next button to process further details.
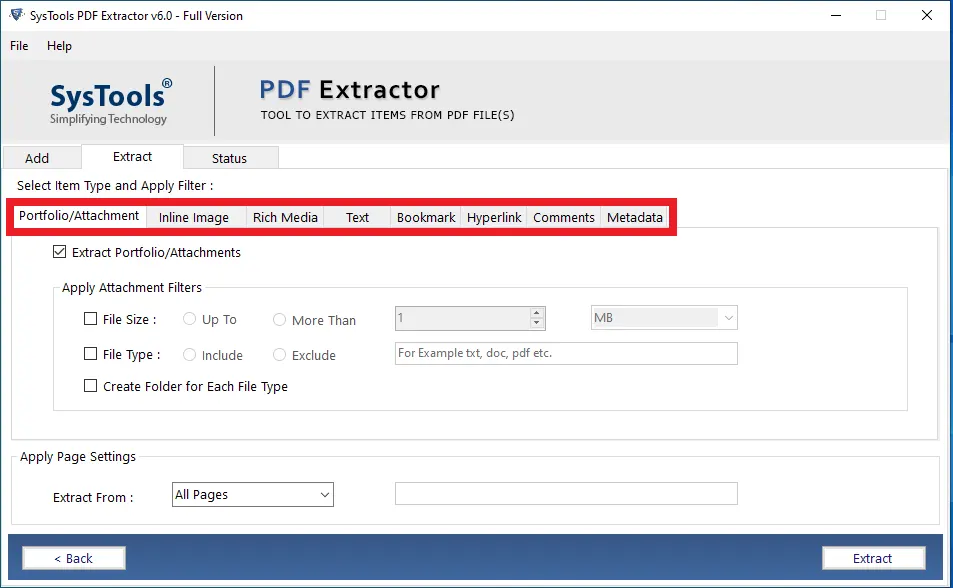
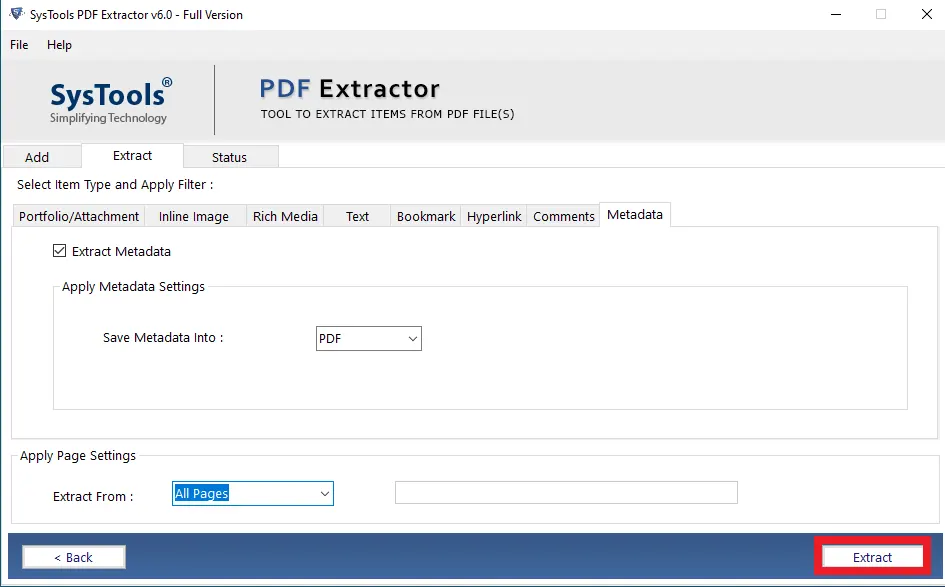
- Now, select the Metadata option and choose the saving format as PDF.
- Then, under the apply page setting option, choose extract from all pages and click on the Extract button.
- After that, the software starts the process to get metadata from PDF.
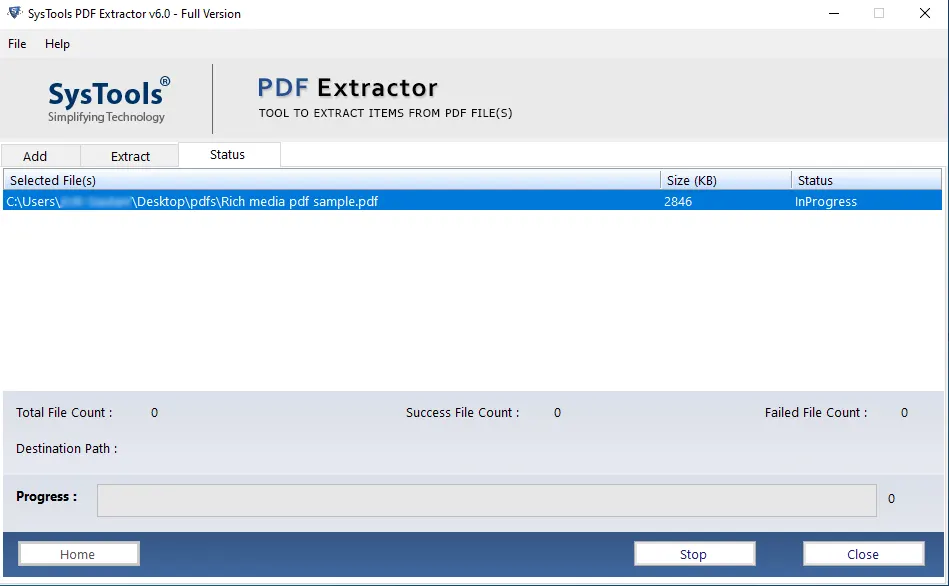
- Finally, complete the process of Extract Metadata from PDF files.
Also Read: Use Quick Ways to Remove a Watermark From a Protected PDF Files
Final Words
In this blog, we will talk about How to Extract Metadata from PDF with the Manual Method and Professional Solution. The Manual Method is the best and most free way to export Metadata from PDF. But the Manual method has some risks and a non-technical person can’t attempt this method. So, it’s better to skip the Manual part and go for a professional solution to get metadata from PDF files. And moreover, this solution has a free demo trial version to check the software features and attempt this method and after you fulfil the software benefits you can go with the license version.
FAQ
Q1. What are the best methods to get the metadata from PDF files?
Technical users can use the Python program to get the metadata from the required PDF files. Non-techie, they can go for the professional tool we have mentioned in this post.
Q2.Does the tool support extracting several metadata from PDF files in bulk?
Yes, using the Add File(s)/Folder(s) option you can extract metadata from pdf files in bulk.
Q3. Can I use this tool on the Mac OS?
Yes, the tool is also available for Mac OS X users other than Windows OS.